
If you have seen or modeled enough optimization problems, you probably came across or felt the need for some big Ms: very large coefficients used as a proxy for infinity. Most often, a big M is used along with a binary variable to turn constraints on or off.
In scheduling, for example, you may use a binary variable y to decide if a job i ends before another job j (ei ≤ sj) when y=1 or vice-versa (ej ≤ si) when y=0. We use M to make the right-hand side of the inactive constraint so large that it becomes irrelevant:
ei ≤ sj + M (1-y)
ej ≤ si + M y
You may like it or not, but no one can be indifferent to big Ms. In fact, many regular attendees and some speakers of the upcoming 2017 MIP workshop have written about it:
- Bob Fourer stressed that M should be “sufficiently big”.
- Paul Rubin cautioned that, if M is too big, it can make the problem ill-conditioned.
- Marc-Andre Carle argued it worsens branch-and-bound by deteriorating bounds.
- Austin Buchanan showed that larger big M-free formulations can be solved faster.
Now…
How bad are the bounds of a linear relaxation with big M constraints?
The. Worst.
You can think of a mixed-integer linear program as a disjunctive program: the union of all linear programs corresponding to fixing the integer variables to every possible value. Ideally, you want the linear relaxation of mixed-integer linear program to be as close as possible to the convex hull of such a union of polyhedra. However, disjunctions represented via big M constraints are as good as nothing for the linear relaxation:
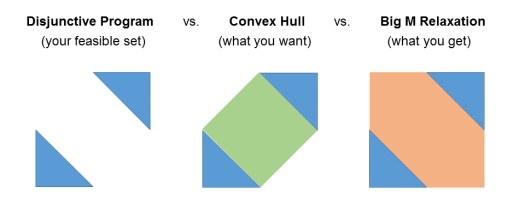
We can see that with a numerical example describing the figure above:
x + y ≤ 1 or x + y ≥ 5
0 ≤ x ≤ 3
0 ≤ y ≤ 3
We can formulate the disjunction as
x + y ≤ 1 + M z
x + y ≥ 5 – M (1-z)
z ∈ {0, 1}
In this case, M=5 is the smallest valid value for the domains of x and y. However, here is what happens if we project out the binary variable z by Fourier-Motzkin elimination:
(x+y-1)/5 ≤ z
(x+y)/5 ≥ z
(x+y)/5 ≥ (x+y-1)/5
The big M constraints vanish in the projection and we are left with the bounds of x and y.
Now…
Is there a way around it?
Yes! And no…
In theory, you can describe the convex hull by lifting the formulation to a much larger space, where we explicitly combine points from different polyhedra. However, the size of the formulation quickly explodes: if you could represent your terms by switching through n pairs of big M constraints, this tighter relaxation will be 2n times larger.
Update: After this post was published, Hassan Hijazi pointed out to his recent work on representing the convex hull in the space of the original variables.
