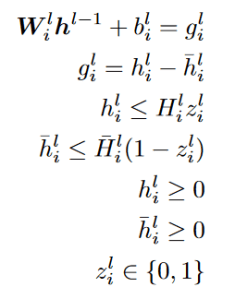There are many things about preparing and presenting slides that I keep repeating to students, so I figured that I should put them down in writing. I do think that they help a lot. (And if I am doing it, why not share it more broadly?)
Tooling:
- Use Power Point if you have Power Point. It is the best and most flexible WYSIWYG tool (“what you see is what you get”).
- Google Slides is an OK replacement. But alternating between Power Point and Google Slides for the sake of sharing files messes up stuff.
- LaTeX is not WYSIWYG and will get you locked into a very peculiar way of doing slides, which I believe is only really suited for mathematicians — or not even them.
- Fancier tools that automatically create pleasing slides will make you look exactly like everyone else trying be cool right now — and they will take away your freedom of customizing things to the limit.
Templates:
- It has been about a decade that widescreen (16:9) replaced the narrower format (4:3). Use the widescreen format.
- Templates should not get the screen crowded with unmovable and useless pieces.
- You do not need more than a line for slide title, so your title can be higher by default.
- You do not need logos and thick bars killing space.
- Unless you want your name and affiliation showing in every slide (may be useful in conference presentations), leave the bottom of the slide free to get a better use of space.
- Add the slide number to help anyone who would like to ask a question at the end.
- The first slide should have your paper title in large font, your name in slightly smaller (but still large) font close to the center, with affiliation in a smaller font right below your name, and then in smaller font at the bottom you can list coauthors and their affiliations.
- Use official templates if convenient (for Iowa: https://brand.uiowa.edu/template-library), mix the official colors in a way that looks pleasing (for Iowa: https://brand.uiowa.edu/color), and observe how logos should be used — someone spent a lot of time thinking this through (for Iowa: https://brand.uiowa.edu/logo).
Content order and depth:
- The number of people paying attention will decrease over time. If you are not the first talk in a session, you may need to do something to impress in them the need to pay attention again. It could be a provocative opening slide, a joke, or something else.
- Start with why your subject is so exciting, and then tell them why it deserves to be more studied.
- If you don’t get to your contribution fast (within 5 minutes), you lose them.
- If you get to your contribution before they understand the context, you lose them.
- If you can mentally anticipate that someone might be thinking something like “that’s not the right way to do this”, address that out loud, so that you keep that person with you.
- Make it easier for everyone to keep following you (easier is a comparison: you can always iterate one more time). Don’t go crazy in unnecessary details.
- If you throw a big formulation on a slide, you just lost almost everyone.
- If you throw a big table with results on a slide, you just lost almost everyone.
- You may want to “take off” at some point and show something very technical and nuanced. The choice of doing that should be based on whether there is one or a few people in the audience that it would be worth to impress, even at the cost of alienating everyone else, which means that you should better do this towards the end, since some people in the audience may “forgive you” and keep following along (at INFORMS in 2012, I decided to prove a theorem in a session about applications because the chair was a CMU professor and I wanted very badly to get into CMU).
- You do not end by claiming that you won and that you beat everyone else who ever tried to solve the same problem: you end by showing that you found a promising way of approaching the problem, and that this helps you understand it better.
- If you can also find the limitations of your work, such as where your approach loses to someone else’s, that communicates a lot more value.
- Scholarship is about learning and exchanging. We win together as a community.
- The last slide should allow the audience to be in touch with you and / or get more information about your work: list of related papers (yours, not the whole literature on the topic), QR code for a preprint or paper, QR code for your LinkedIn profile, social media handles, personal website, etc.
- You stop at the slide with your papers and contact information and stay there. Leave it for as long as you can, so that the audience can take a picture or open the QR code.
Slide content:
- It is almost never a good idea to use a font smaller than 28. You are preparing slides, not writing a paper.
- Think about every line and every bullet point as the thing that you should be talking next. What you put in the lines and bullet points is just a very condensed version of what you are saying, which helps you cover what is important and let people get the gist if they miss you for a short while.
- You don’t want the audience to be reading the slides instead of paying attention to what you say, so use Animations (in Power Point) to control when every little thing on the slide will appear — and in what order.
- If you show an image, that takes some processing time too. Don’t put a cartoon with speech bubbles as the first thing to appear on a slide — unless this slide is meant as a break for you to slow down, drink some water, and the cartoon does have a connection worth risking this.
- GIFs, memes, and popular culture props are awesome — if they help dramatize the point that you are trying to make. But be mindful of how they may end up stereotyping specific groups, or how your choices may consistently prioritize one group over others.
- Plots may deserve their own presentation version, which may be different from how they look in your paper. A poor copy–paste from the paper looks bad on you.
- When you show a plot, you need to tell your audience how to read it.
- Do not present something that you have not prepared yourself, or at least thoroughly revised yourself, or at the very least practiced enough times to get the gist of it. Do not trust AI on doing anything that you are not going to perfectly understand before using.
Practicing it:
- Practice your talk enough times that you know it by heart.
- In the worst case, you can just repeat that memorization word by word. In case you do that, just try to make it look natural as much as you can. Put some pauses and emotion in it.
- A better approach is to break away from the memorized script by paying attention to the audience, improvising, and finding better ways of expressing the idea on the spot. In other words, make it look natural by making it actually natural. But it takes practice to make it sound as if you have not practiced it!
Remember George Orwell:
- Politics and the English Language is one of the best essays about good writing. I recommend reading it periodically (https://www.orwellfoundation.com/the-orwell-foundation/orwell/essays-and-other-works/politics-and-the-english-language/).
- See how it adapts to what was covered here — in my opinionated view:
i. Never use a metaphor, simile or other figure of speech which you are used to seeing in print. [don’t do something just because other people are doing it — keep things simple and direct]
ii. Never use a long word where a short one will do. [make it easy to understand]
iii. If it is possible to cut a word out, always cut it out. [make it short and to the point]
iv. Never use the passive where you can use the active. [keep language simple to read]
v. Never use a foreign phrase, a scientific word or a jargon word if you can think of an everyday English equivalent. [nobody cares for the complex terms, the long formulations, etc]
vi. Break any of these rules sooner than say anything outright barbarous. [memorize the script only to break away from it; and do not take anything that I am saying as unbreakable: follow your instincts and create your own style]